



If you’re not measuring communications, you don’t know it’s working.
Yet our profession has a strange relationship with evaluation. We oscillate between self-flagellation and procrastination. We tell ourselves we need to do it better. Then decide it’s all too difficult and carry on as before.
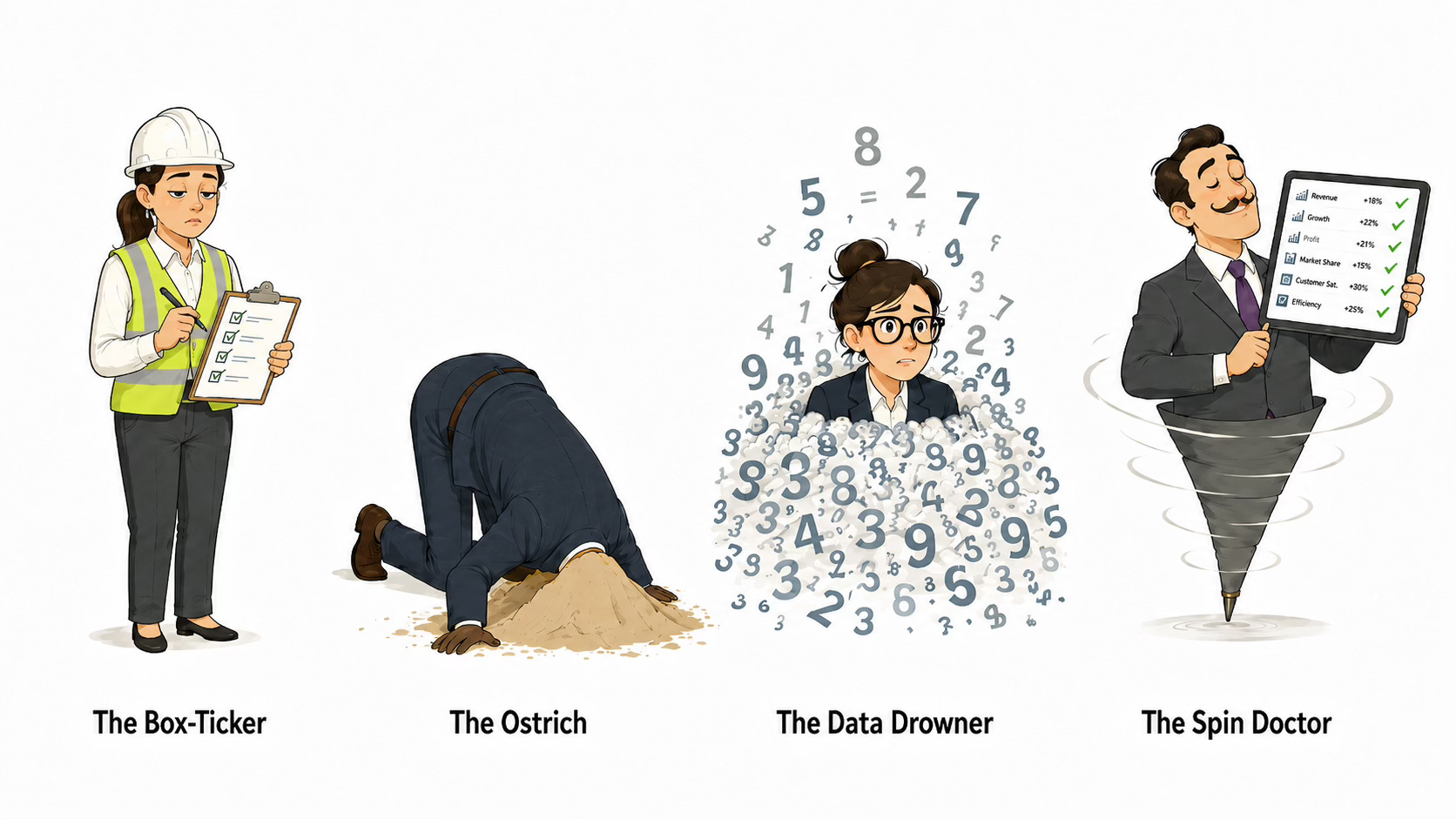
I have observed four communications evaluation archetypes:
The first are The Box-tickers. They know they are expected to care about evaluation, but treat it like a tiresome compliance issue. They count what’s easy rather than what matters, put it in a report and never look at it again.
Second are The Ostriches. They avoid stretching targets for fear of bad news. Their biggest worry is that their evaluation might show their communication isn’t working. And they’d rather learn nothing than risk being seen to fail.
Third are The Data Drowners. They are the enthusiasts. They know every measurement framework and metric. But they can’t see the insight for all the data. They know every data point, but not what to do next.
Fourth are The Spin Doctors. Their evaluation dashboard always glows green. Every month is a success. Every metric has improved. But if a number looks awkward it is simply replaced with another. Apparently the comms are going great, but the business results haven’t changed at all.
These may be caricatures, exaggerated for effect, but I saw a little of each of them when I used to visit government departments to review performance. These behaviours are not individual failings, they are symptoms of a system that rewards the wrong evidence.
What we are getting wrong
The heart of our evaluation problem is this: we’re counting the wrong things for the wrong reasons.
We measure what is easy to count. Coverage, followers, impressions. But these are an illusion of reach and impact. As Professor Jim MacNamara has pointed out: the number of impressions is not the number of people impressed. That captures the deeper problem: not everything that can be counted counts and not everything that counts can be easily counted1.
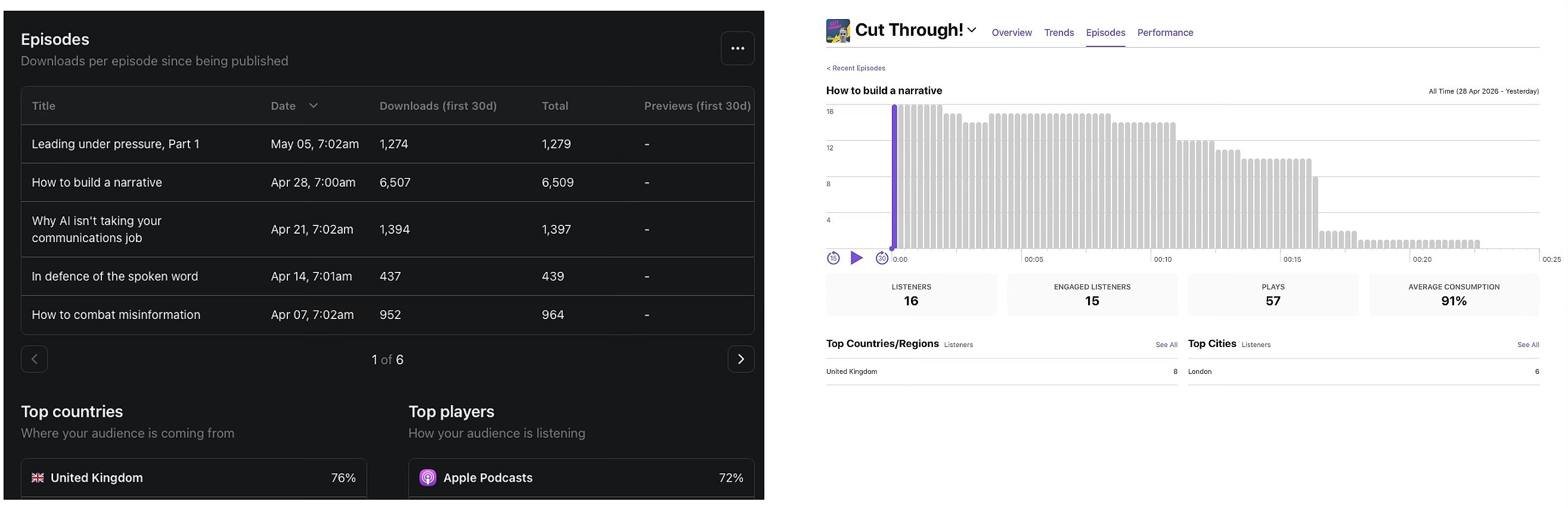
Too many of the numbers we report are meaningless. Take the reported podcast downloads for my recent article on ‘How to Build a Narrative’. Substack’s dashboard showed 6,507 downloads, with 72% on Apple Podcasts. I was sceptical, so I checked the Apple Podcasts dashboard. It shows 16 listeners and 57 plays for the same episode. What sensible conclusion is anyone supposed to draw from that?
Many in our profession recognise that we need to move beyond vanity metrics to numbers that matter.
Fewer recognise that we’re also measuring for the wrong reasons. I frequently hear evaluation talked of as a way to “prove the value of the function”. That is understandable. Corporate affairs leaders work in organisations that prize hard numbers. Boards want evidence of impact, and we’re competing for budget and attention.
But it is precisely this focus - numbers to prove worth - that causes people to choose metrics that make them look good. If people fear that bad results carry personal consequences, they avoid ambitious targets. If dashboards are used for board theatre, people play for applause. That is how you get Ostriches and Spin Doctors.
The purpose of evaluation should be learning. Done properly, it is the difference between doing communications and improving communications. It tells you whether your work reached the right people, whether it changed their minds, whether they took actions as a result, and what you should do differently next time.
The strongest way to demonstrate value is with evaluation that works. A function that can genuinely explain to the board what is driving support or increasing stakeholder risk is far more valuable. But it comes with the short-term pain of admitting some things may not be working.
The final thing that makes measurement hard for corporate affairs is that the assets we protect are real but are hard to value or isolate: trust, licence to operate, political and regulatory risk, reputational resilience. These affect whether people buy from you, invest in you, defend you or attack you. But they are difficult to quantify and they rarely move because of communications alone.
What good evaluation measures
So what does good communications evaluation look like?
The formal models of evaluation, such as the AMEC Barcelona Principles and the GCS Evaluation Cycle, are rightly seen as best practice. But for most communicators, I think an easy framework to keep in your head involves asking three simple questions:
Did we deliver what we said we would do? Outputs.
Did people think differently as a result? Out-takes.
Did anything change in the real world as a result? Outcomes.
Outputs are the activity and exposure: briefings held, stakeholders reached, channels used, coverage secured. Outputs still matter because they measure whether you delivered what you planned to do. But they are only the start.
Out-takes are what audiences heard, understood, felt, believed or intended to do as a result. This is the test of whether your message landed. Did it have the desired effect of getting your audience to think or feel differently?
Outcomes are what changed as a result. Did your audience’s behaviour change? Did stakeholders act differently? Did a regulator decide not to act? Did investors gain confidence? Did a campaign group shift its position?
It becomes progressively more difficult to evidence each step and especially difficult to directly attribute the outcomes to communications activity alone.
Good evaluation should be honest about what is known versus inferred and not make exaggerated claims of causation. But that is not an excuse for stopping at outputs.
Ultimately, the purpose of a communication function is to influence behaviour or attitude in a way that benefits your organisation. If you’re not measuring that change and its impact then you cannot say whether you were successful.
How AI changes evaluation
The bad news is that AI will not automatically solve our evaluation problem. In fact, it may make it worse.
It is already giving us a lot more data, faster. It can summarise enormous amounts of coverage (but is also creating huge amounts of new content), it can classify audience sentiment (but is further fragmenting audiences), and it can quickly spot patterns and generate plausible conclusions (but plausible is not the same as accurate).
AI can be helpful but only if used in the right way. If the profession already has a habit of counting what is easy rather than what matters, then AI could industrialise that bad habit. It can help Box-Tickers tick boxes faster, Data Drowners swim in ever larger data lakes, and Spin Doctors produce ever-more polished but useless dashboards.
There is another risk for AI evaluation too. Many large language models are built to be helpful and encouraging. If I simply ask AI to review a campaign, I risk hearing: “This might be your best campaign yet, Simon!” That means prompting for challenge. Used badly, AI will give false confidence from weak evidence.
We need human judgement to help interpret AI. But those humans must want to learn whether they are really having impact. A lot of incentives will be pulling in the opposite direction.
AI can offer real help in three places. First, weak-signal detection: drawing intelligence from large volumes of material that no team could read manually, and being able to spot emerging risks before they are obvious. Second, message gap analysis: comparing what organisations intended to communicate with what an audience appears to have heard or repeated. Third, alternative explanation testing: challenging whether a movement in the metrics was caused by communications or whether other changes or events may have played a role. AI cannot prove causation any more than we can, but it can make our evaluation more curious and useful.
How to put it into practice
Here’s how to put good evaluation into practice today:
Define success before you communicate. One of the biggest issues is unclear objectives. If the objectives are vague (“protect reputation”) then it will always be difficult to measure impact. Be clear at the start what impact you are trying to have for the organisation, what audience behaviour you are trying to influence, and what your strategy is for doing that. Only once you have established this and your baseline do you have a chance of measuring whether you achieved anything.
Have a clear strategy for the role of communication. Every campaign should have a hypothesis or theory of change. At the simplest level this sets out what your audience thinks, feels or does today (your baseline), what communications you are going to deliver, and the effect you hope to have. That allows you to test it against outputs (the comms you will deliver), out-takes (what the audience now thinks or feels) and outcomes (what they did differently).
Separate output from out-takes and outcomes. Measuring outputs still matters because they tell you whether you executed your strategy successfully. If you didn’t deliver the outputs successfully, then that is the primary reason why the campaign failed. Whereas if you did execute successfully and there was no impact on out-takes or outcomes, then it is the strategy that needs changing not the delivery.
Build a live feedback loop. Evaluation no longer needs to be post-mortem. Think about how you can capture data that allows you to test effectiveness as you go using small experiments, for example with small A/B tests where you test two variants at the same time to see which performs best. That could be different messages, timing, spokespeople or formats.
Create the right culture. If people are punished for bad results they will hide them. If evaluation is celebrated as learning it will drive improvement. That means leaders at all levels, changing the way they talk about evaluation - not “did this work?” but “what have we learned?”. Some of the best organisations create a ‘learning of the week’ award to deliberately reward people who have found evidence of something not working that can be improved.
That culture also needs an honest conversation with senior leaders and the board. One in which corporate affairs directors take control of the issue by saying:
"I don’t think our communications evaluation is good enough. I’m going to change it so that it gives us more valuable insight and learning. But a more rigorous approach is likely to show that not everything works today. The team needs to know that’s a good thing, because it will help us improve, not something that will leave them exposed. Do I have your backing for that?”
That is how Corporate Affairs teams prove value and build trust. Not by showing they are always effective, but by showing they are serious about learning what works. Better learning will produce more credible evidence of value.
Bad evaluation is mainly caused by bad incentives rather than a lack of knowledge. People count weak metrics because they are available. They avoid stretching targets because they fear the consequences of missing them. They create green dashboards because leaders celebrate success rather than learning.
Changing that is a culture and behaviour issue, as much as a measurement issue. Better tools might help. But if we want better evaluation then we need to reward the behaviour that produces it: curiosity, honesty, and continuous improvement.
This quote is often attributed to Einstein but the attribution appears shaky.

